CloudWeGo-Netpoll ,以下简称为 Netpoll,是由字节跳动开发的一款专注于 RPC 场景的高性能 NIO 网络库。大大多基于多路复用的网络库,基本框架都比较类似。但不同的网络库会针对不同的应用场景对基本框架进行修改,从而使其在固定场景下发挥出更好的性能。本文着重分析 Netpoll 与其他网络库不同的设计,以及这些设计是如何满足 RPC 场景的。
Netpoll 场景
RPC 场景,在我的理解中,主要可以由以下几个特点来概括:
- 较重的处理逻辑,事务处理中可能会有较长时间的阻塞;
- 通常采用短连接或者长连接池的形式;
- 具有超时机制,可能会产生较多的失效连接。
在这种场景下,使用 go 标准网络库开发服务端比较方便,但无法达到较高的性能,这主要来源于 goroutine 的调度开销上。在微服务场景下,服务器之间的交互非常频繁,服务器 A 到服务器 B 之间可能会需要多条 rpc 逻辑连接,如果为这些逻辑连接全部开辟出一条物理连接,会对服务端和客户端都造成比较大的压力。通常,rpc 框架会选择使用多路复用的方式,避免开辟过多的物理连接。但又因为 rpc 依赖链路这种情景,串行处理 rpc 是性能非常低下的。当使用标准网络库时,虽然 rpc 的解析在阻塞 IO 下也可以实现多路复用,但是 rpc 的处理逻辑必须要开辟一个新的 goroutine 来防止队首阻塞。这是因为 rpc 可能是具有依赖链路的。通过分析,我们可以发现,使用 go 标准网络库进行开发,虽然可以避免开辟过多 goroutine 用于解析,但是仍然需要为每一条业务逻辑开辟出一个 goroutine。当 goroutine 过多时,调度器的压力会比较大,造成较大的延迟。
而 go 语言的一些其他网络库如 gnet,底层会使用 ring_buffer 作为缓冲区(新版本中也可以作为 linked_list 作为缓冲区)来获取更高的性能。由于 ring_buffer 中内存地址是会被复用的,并且生命周期难以被管理,如果应用层的业务逻辑没有阻塞的情况下,可以直接在读事件中的 callback 中完成事件处理(如 redis 的 500us 左右的纯内存操作,HAProxy 的转发操作),那么这种网络框架性能是非常高的,核心点就是不需要分配内存。但是在 rpc 场景下,业务的处理逻辑非常重,仍然需要分配内存进行拷贝,防止 ring_buffer 被覆盖,这种框架的优势就没有那么明显了。(当然,可以在业务层自行实现内存池来解决这一问题,不过这相当于把问题抛给了用户)
综上所述,Netpoll 所要做的,核心有两点:
- 实现非阻塞读写,避免开辟过多 goroutine;
- 实现生命周期可调控的内存复用,避免分配内存。
高性能网络库“三板斧”
各种实现的 Reactor 模式,其高性能主要来自于避免了各种耗时操作,如内存分配、线程开辟、互斥量竞争,几乎所有的高性能网络库都做了以下几点优化:
- Multi-Reactors/Master-Workers 模型,避免 epoll 惊群效应;
- EventLoop 模型的高效运行机制;
- 高效的内存管理机制,尽量避免内存分配;
- 高性能线程/goroutine池,避免用户手动开辟处理异步逻辑。
这几点在 Netpoll 中都有涉及,其中内存管理是借助 sync.Pool 和 link_buffer 实现的;高性能协程池则是使用了自家的 gopool。
Reactor 模式实现
Netpoll 中使用的是主从 Reactor 模式,能够有效地避免 epoll 惊群效应。主从 Reactor 模式实现上的一个细节问题是如何进行 fd 的传递,即系统调用 accept 获得的 fd 如何注册到 Worker Reactor 的 epoll 上。在 muduo 和 gnet 的实现中,都是以队列的形式进行传递;而在 Netpoll 实现中,则是直接在 Master Reactor 线程使用 epoll 系统调用将新到达连接的 fd 注册到 Worker Reactor 上。
Netpoll 中处理新连接到达的代码比较分散,这里简述一下调用链:server.OnRead -> connection.init -> connection.onPrepare -> connection.register -> FDOperator.Control -> poll.Control
上述调用链是发生在 Master Reactor 线程中的,这是利用了 epoll 线程安全的特性,当使用 epoll 相关系统调用时会使用自旋锁来保证红黑树结构的线程安全。poll.Control函数会根据输入参数使用不同的系统调用来维护 epoll 的注册表。
1 | // Control implements Poll. |
当新连接到达时,FDOperator.event == PollReadable 或者 FDOperator.event == PollModReadable,因此该函数会将新到达的 fd 注册到对应的 poll 结构体上。
Nocopy Buffer
Nocopy Buffer 是 Netpoll 设计的核心内容,连接多路复用、ZeroCopy 优化都是基于 Nocopy Buffer 结构的。
linkBuffer 数据结构
Nocopy Buffer 本质上是一个基于链表的无锁读写结构,链表的节点是linkBufferNode数据结构。
1 | type linkBufferNode struct { |
linkBufferNode本质上是一个可引用、具有读写标识位的缓冲区,由于单独对读标识位和写标识位操作是可以并发的,所以其是一个单读写可并发的无锁结构。
linkBuffer则是linkBufferNode组成的链表,其数据结构如下:
1 | type LinkBuffer struct { |
linkBuffer中使用四个标识位来描述当前的读写状态。head 指向链表的头部,head 与 read 节点之间是可以被释放的节点,read 至 flush 节点是当前可读的区域,flush 至 write 节点是当前可以写入的区域。
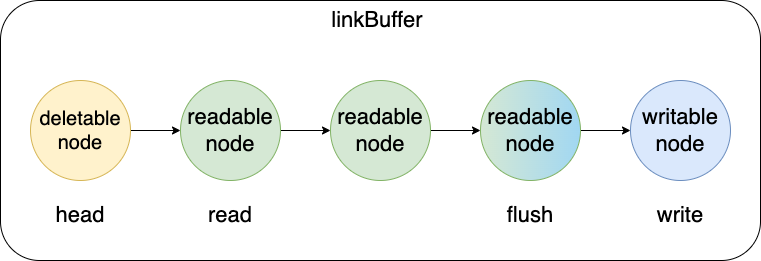
flush 节点指向的 node 是渐变的,代表其中一部分区域是可读的,一部分区域是不可读的。因为同一个节点可能会被同时写入和读取。虽然图中未指出,但是 head 与 read 节点也可能重合,可以被安全释放的范围是 [head,read) 。
Nocopy 体现在哪
linkBuffer 具有 nocopy 特性,但并非所有的接口都是 nocopy 的。
linkBuffer 的所有读接口的处理逻辑都是类似的,这些读取操作是否为 nocopy 取决于读取的位置。以 linkBuffer.Next函数为例,分析什么情况读取是不需要拷贝的,代码只保留了用于分析的部分:
1 | func (b *LinkBuffer) Next(n int) (p []byte, err error) { |
linkBuffer.Next函数中的读取一共具有两种情况。第一种情况是读取的长度小于 read node 的剩余可读取长度,在这种情况下并没有使用 copy 操作,而是复制了地址,这种情况下是 nocopy 的;另外一种情况是读取的长度大于 read node 的剩余可读取长度,这时候需要将分散在各个节点的数据拷贝到一起,如果要求的数据过长,甚至可能会发生多次拷贝。为了避免出现多次拷贝的情况,应该设置linkBufferNode.buf的长度大于用户需要读取数据的平均长度。
另外值得注意的是,函数中还会根据用户要求的长度来决定不同的内存分配策略。当用户需要的长度过大时,会考虑从内存池中获取一块内存,并将这块内存保存在 caches 数组中,再选择合适的时机将内存归还内存池。
linkBuffer 的写接口只有一部分是 nocopy 的,即linkBuffer.Malloc函数。
1 | func (b *LinkBuffer) Malloc(n int) (buf []byte, err error) { |
函数的逻辑也非常简单,就是在链表中找到一个连续的内存区域,然后将该内存区域返回给用户。如果所有的内存区域都不足以写入,那么将分配一个新的节点,该节点大小正好为用户要求的区域。
1 | func (b *LinkBuffer) growth(n int) { |
linkBuffer.growth函数很好地封装了分配新节点和寻找内存区域的功能,这个函数还是比较好的。注意到,函数中有一段逻辑是跳过了所有的只读节点,那么什么情况下会出现只读节点呢?linkBuffer 中只读节点只来源于用户的接口函数linkBuffer.WriteDirect。该函数可能会导致用户方的乱序写入,因此可能会出现下图中的情况。
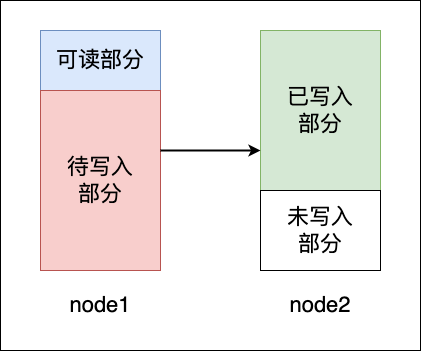
用户在获取内存后,首先写入了 node2 中的部分,而 node1 中虽然仍有空白内存,但该内存已经被用户 hold。此时,如果用户又调用了一次写入操作,必须将数据写入到“未写入部分”,因为“待写入部分”后续会被其他写操作覆盖。linkBuffer 实现中的做法是直接将 node1 设置未 readonly 状态,这里的 readonly 并不是完全禁止写入,而是禁止再从该节点上获取位置进行写入,已经获取位置的区域仍然是可以写入的。
为什么是无锁的
linkBuffer 可以用作读缓冲或写缓冲,由于每一个 connection 都会被分配到一个 poller 上,在读缓冲区时,poller 底层只会对 poller 进行写入(接收数据),在写缓冲时,只会对 poller 进行读取(发送数据)。所以无论哪种情况下,Netpoller 都保证框架对缓冲区的读写是单线程的,由于读与写操作使用了不同的标志位,因此只要用户可以保证也使用单线程进行读写,就能够保证 linkBuffer 的无锁并发访问。
连接多路复用
连接多路复用这个概念是存在于客户端的,服务端中不需要连接多路复用。Netpoll 在客户端实现连接多路复用的基础是非阻塞 IO,而 linkBuffer 则是实现高性能的多路复用手段。同时,由于连接多路复用是协议依赖的,NetPoll 只是提供了多路复用的支持,并在官方 blog 中给出了可行的方案。
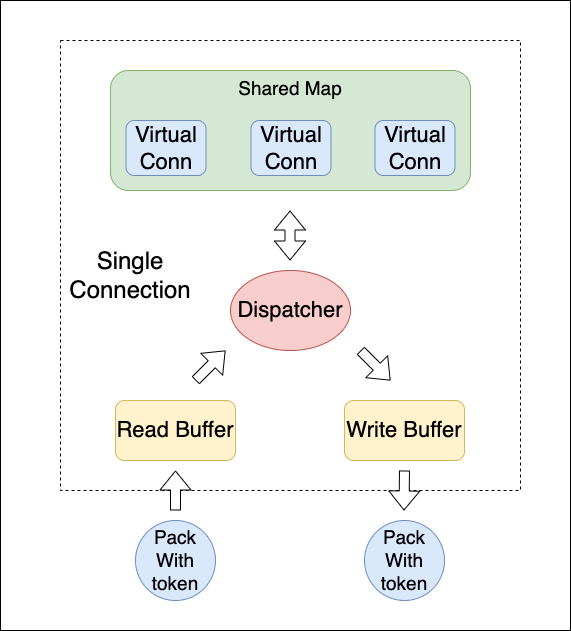
连接多路复用方案包含以下几个要素:
- Virtual Connection:建立在真实连接之上的虚拟连接,具有一个 uuid 用于区分;
- Shared Map:根据 uuid-virtual conn 的方式来存储虚拟连接;
- Dispatcher:用于读取并解析数据包,根据数据包中的 id 选择对应的 Virtual Connection;
- Rpc Protocol:一个支持多路复用的通信协议。
方案中,一个真实连接能够承载多个虚拟连接。这些虚拟连接都通过一个分发器来间接与读写缓冲区交互,虽然多个虚拟连接可能运行在不同的 goroutine 中,但是读写操作最终只能够由 Dispatcher 来处理,因此 linkBuffer 之上依然是一读或一写,能够保持无锁并发的特性。Dispatcher 在读取数据后,可以不拷贝数据,而是直接返回对应的切片位置,不同虚拟客户端之间操作不同的切片位置,仍然能够保证无锁并发。
ZeroCopy
Netpoll 目前并不提供 zero copy 的支持。如果要使用 zero copy 的系统调用,就必须要保证需要发送的数据在被内核拷贝掉网卡没有被释放掉。这对于 Netpoll 的框架来说会比较麻烦,因为 linkBuffer 每一次在进行写入时,会根据写入的字节长度来对内存区域进行释放。被释放的内存会进入可 GC 状态或进入内存池,这两种状态下都不能够保证内存的存活周期。如果想要在解决这个问题,可能需要大幅度修改代码框架。
NetPoll 的官方博客中有这样一段介绍,我不太能够理解:
于是,字节跳动框架组和字节跳动内核组合作,由内核组提供了同步的接口:当调用 sendmsg 的时候,内核会监听并拦截内核原先给业务的回调,并且在回调完成后才会让 sendmsg 返回。 这使得我们无需更改原有模型,可以很方便地接入 ZeroCopy send。同时,字节跳动内核组还实现了基于 unix domain socket 的 ZeroCopy,可以使得业务进程与 Mesh sidecar 之间的通信也达到零拷贝。
这样是让 sendmsg阻塞直到将内核将内存写入,如果在写入速度比较频繁的情况下,这样会不会导致写入操作被阻塞过长时间。