应用缓存具有两种形式:缓存服务和进程内缓存。在大部分情景下,缓存服务已经可以解决应用缓存问题;但由于缓存服务需要经过网络通信,其性能一般是不如进程内缓存的。当性能要求较高时,就需要考虑采取进程内缓存的方案。并且,进程内缓存可以直接寻址,因此不仅可以缓存字符串,还可以缓存更加复杂的数据结构。不过同样地,进程内缓存也具有其缺点,诸如维护较为困难、缓存难以共享、影响进程内其他模块性能等。
一般而言,设计进程内缓存主要需要考虑以下几个方面的问题:
- 应用于高并发、高性能场景,需要较高的并发性能;
- 内存管理策略,如缓存淘汰机制,防止占用过多资源;
- CPU 占用低,不影响进程内其他模块的性能;
- 存储灵活多变的数据结构,如会话 token 等。
freecache 和 bigcache 是两个比较出色的使用 go 语言的进程内缓存的开源项目;另外 bigcache 还有一个衍生类项目 fastcache。下文将从进程内缓存需要考虑的几个问题出发,对比着几个项目的异同点。
实现高并发
freecache 和 bigcache 中实现高并发的策略是相同的:哈希表分片来减小锁的粒度。
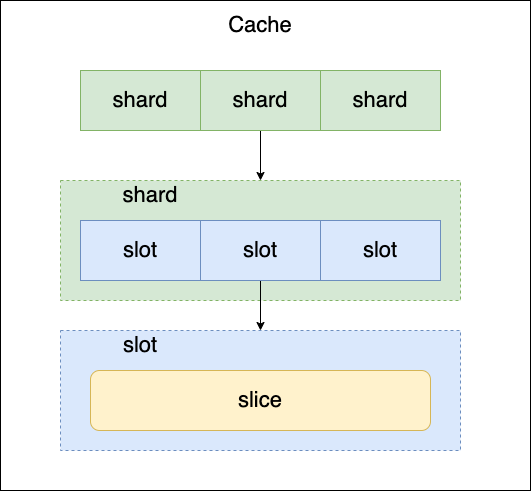
由于哈希表的时间复杂为 O(1),因此进程内缓存应当首选哈希表为数据结构;但由于哈希表并不是一个线程安全的数据结构,必须加锁来保护,并发的线程数量较多时,直接对哈希表进行加锁性能会非常差。哈希表分片是通过哈希值的方式将大哈希表拆分为多个小哈希表,这样只需要对每一个小哈希表进行加锁保护即可,这种方式降低了锁粒度,可以大幅度提升并发性能。这种处理比较常见。
CPU 占用(GC)
由于 go 是一种 GC 语言,进程内缓存就不得不考虑垃圾回收对性能的影响。在 go 中,使用指针、哈希表等非内存连续的结构会导致 GC 的时间大幅度增加,freecache 和 bigcache 中的设计都考虑到了这两点。虽然工程实现上有所区别,但是两者的核心思想都是相同的:使用线性数据结构来存储键值对,利用哈希表来存储地址偏移量,从而避免 GC 耗时。使用简单的代码就可以描述其原理:
1 | origin := make(map[string][]byte) |
freecache 中并没有使用 go 自建的哈希表作为索引,而是使用哈希函数加 slice 的形式自行搭建了一个哈希表;bigcache 中则是直接使用了 go 自建的哈希表作为索引。不考虑哈希函数优劣的前提下,freecache 这里的设计更好,因为只需要计算一次哈希值即可,而 bigcache 中则需要计算两次哈希值。
在线性存储结构方面的区别主要在于,bigcache 是支持自动扩容的(使用拷贝的方法)。
数据结构的支持
C++ 实现的进程内缓存通常都支持存储多种数据结构,不仅可以存储字符串、还可以存储更为复杂的数据结构;在网络服务器中,就可以使用本地缓存来存储 tcp 连接的描述符。而 go 实现的进程内缓存一般只支持存储字符串,复杂的数据结构只能够经过序列化后存储在缓冲中,这一方面是因为 go 在 1.18 版本前并不支持泛型,另一方面是因为 go GC 机制的存在。
理论上,不使用泛型,只使用interface{}也是可以实现存储不同的数据类型的,并且不会给 GC 带来额外的压力;但是问题在于,如果存储的数据结构比较复杂的话(比如数据结构中存在指针),也会大幅度影响 GC 的性能。使用以下实验分别测试在 1000W 数据量情况下,go GC 的时间;以下几组测试分别在不同的进程中完成,不存在相互的影响:
1 | // 简单数据类型,不含指针 |
四组的 GC 时间在 go 1.19 版本经过测试后,分别如下:
1 | s1 GC time: 328 us |
对比 s2 和 s4 可以看到,当数据量比较大时,内部含有指针的数据结构所需要耗费的 GC 时间甚至达到了约 20ms,相比于简单数据结构增长了 58 倍左右;这是一个比较可观的延迟。另外,对比 s1、s2 和 s3 三组实验,在切片中使用指针同样会导致全量的 GC 扫描,否则会导致 GC 时间大幅度增加。
由以上的实验,我们可以得出两个结论,go 实现的进程内缓存,如果要存储复杂数据结构,就必须使用非指针形式存储,并且要求数据结构内部尽量不存在过多指针,否则会导致性能大幅度降低。但这会带来一个问题:复杂的数据结构本身占用的内存可能会较大,每次写入和读出缓存时都会涉及到一次全量复制,这是非常耗时的一个过程。
针对这一点,我觉得可以结合sync.Pool的思路来实现零拷贝写入:在进程内缓存内部设置一个 hook 函数,用户可以通过设置 hook 来控制缓存所存储的数据类型,当用户需要时,直接将对象构造在缓存的内部,然后返回用户指针,这样就可以节约写入时的拷贝。并且,缓存内部失效的数据结构也可以被复用,可以节约对象构造的时间。
性能对比
根据 bigcache README 中的 benchmark 测试结果,freecache 在性能上会比 bigcache 略低,这里贴出 v3.1.0 版本,bigcache 主页的测试结果:
1 | go version |
两者的代码结构其实比较类似,差别之处主要在于过期键的清理、哈希表的实现方面;肉眼是无法观察出两者的优劣的,使用 pprof 工具来分析 benchmark 时 freecache 的 CPUProfile,得到以下的结果。

根据火焰图,可以看出 freecache 的写入流程中,函数segment.lookup()和Timer.Now()两个函数的耗时时间是比较长的。其中segment.loopup()函数的主要功能是处理哈希冲突,火焰图中大规模出现该函数证明了 freecache 中的哈希函数是略微欠缺打磨的,并且解决哈希冲突时,freecache 需要比较 slice 值,这也是一个性能比较差的地方,即火焰图中的 函数freecache.(*RingBuf).EqualAt。
另一点,则是Timer.Now()函数的耗时,我们看一下 freecache 中的 Timer 实现:
1 | // Helper function that returns Unix time in seconds |
由于每一次 Write 都会使用一次时间戳,所以使用defaultTimer会带来非常严重的性能问题;经过查看源码,作者这里提供了另外一个 cachedTimer,它会缓存一个时间戳,并使用一个 goroutine 维护,每秒钟更新一次;但是并没有将该定时器作为 benchmark 代码中的默认定时器。将定时器修改后,该部分耗时可以忽略不计,这里不再放测试结果。
用户接口
freecache 提供了几个较高性能的用户接口:
1 | // 查询后将值作为输入调用函数 fn |