Go 中的 GC 实现比 Lua 要更为复杂,复杂度主要来自于:指针类型、struct 类型、物理机环境。指针类型和 struct 类型使得 GC 扫描更加复杂,并且在物理机环境下对象的视图是内存段。另外, Go 主要用来编写大型的程序,如果使用类似 Lua 的 Header,可能会耗费比较多的内存,是不现实的。
在 Go 语言中,编译器会在编译期为每一个 struct 类型生成一个_type类型的对象,并且记录在 runtime 中。该类型的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
type _type struct { size uintptr ptrdata uintptr// size of memory prefix holding all pointers hash uint32 tflag tflag align uint8 fieldalign uint8 kind uint8 alg *typeAlg // gcdata stores the GC type data for the garbage collector. // If the KindGCProg bit is set in kind, gcdata is a GC program. // Otherwise it is a ptrmask bitmap. See mbitmap.go for details. gcdata *byte str nameOff ptrToThis typeOff }
反射是 Go 语言中较为难以理解的一个特性,网上讲解反射的文章有很多,但是要么讲解细致但是篇幅过长,要么讲解稍微模糊。但其实如果掌握了反射所使用到了一些技术,反射本身是很好理解的,其原理就是一个向上和向下转换的过程。本文会从反射所基于的语言特性出发,简要地分析反射这一特性是如何实现的。
unsafe.Pointer
在讨论unsafe.Pointer之前,我们先来讨论一下 C 语言中的原始指针类型以及指针之间的相互转换。在 C 语言中,所有指针都是可以相互转换的,而对指针取值其实就相当于取当前指针所声明类型长度的一段内存。我们可以利用 C 语言指针的这种特性在不同长度的结构体实现变换,最为经典的例子是 linux 链表。Go 中同样也有指针,但由于 Go 是一种 GC 语言,如果保留 C 指针的这样灵活性,将会对 GC 扫描带来很大的挑战,如果一个指针向上转换了,那么很有可能会造成内存泄露的问题。
为了实现 C 语言中这种灵活转换的特性,Go 中引入了unsafe.Pointer这一类型。unsafe.Pointer是 go 中用于实现类型转换的一种中间类,我们可以将一个长度为 n 的unsafe.Pointer视作是一个长度为 n 的数组(即内存中的某一段数据),但是这一段数组中的数据对用户来说是不可见的。在某种意义上来说,unsafe.Pointer是用来告诉 GC 扫描器这段内存已经被分配,如果需要进行垃圾清理,必须释放这段内存,防止内存泄露。在 C++ 中,这一特性是通过将析构函数作为虚函数来实现的。
为了更直观地表示这一功能,以一个代码实例来演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
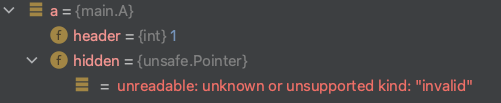
type A struct { header int hidden unsafe.Pointer // 占位,该字段的所有信息对用户隐藏 }
type B struct { header int toHide int// 将会被隐藏的字段 }
funcmain() { b := B{1, 1} var a A a = *(*A)(unsafe.Pointer(&b)) }
在 go 语言中,为了实现反射大量使用了这一特性,如果对这一特性不了解,建议先学习一下 linux 中的链表实现,这将有助于理解 go 的反射原理。
eface 和 iface
eface和iface是 go 中非空接口与空接口的底层实现,其原始定义代码出现在 runtime2.go:202:
1 2 3 4 5 6 7 8 9
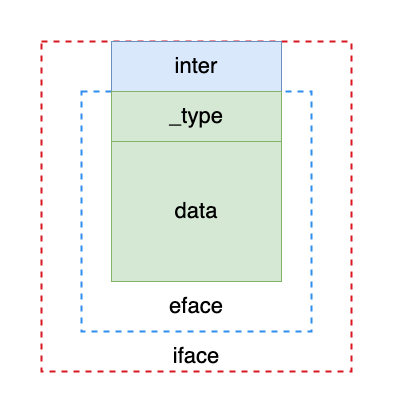
type iface struct { tab *itab // 存储接口与原始类的类型信息 data unsafe.Pointer // 存储原始类的其他信息 }
type eface struct { _type *_type // 存储原始类的类型信息 data unsafe.Pointer // 存储原始类的其他信息 }
我们将代码展开,来比较两个结构体之间的差异:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
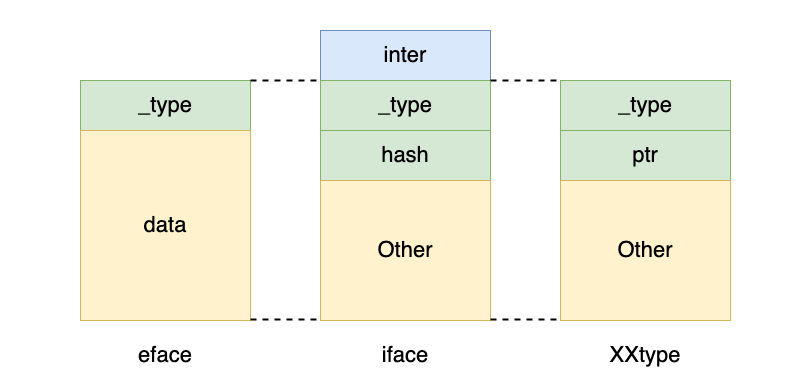
type iface struct { // 原 tab 字段 start inter *interfacetype // 存储接口类型信息 _type *_type // 存储原始类的类型信息 hash uint32// copy of _type.hash. Used for type switches. _ [4]byte// 占位,4 字节 fun [1]uintptr// variable sized. fun[0]==0 means _type does not implement inter. // 原 tab 字段 end
data unsafe.Pointer // 存储原始类的其他信息 }
type eface struct { _type *_type // 存储原始类的类型信息 data unsafe.Pointer // 存储原始类的其他信息 }
注意这两个类型展开后的区别,iface在起始位置比eface多了一个 inter 字段,该字段用于存储接口信息,这是为了比较不同的非空接口是否相等;而iface和eface的最后一个字段都是unsafe.Pointer类型。暂时不考虑其中存储的数据类型,将iface.hash字段至iface.data字段也都视为字节(这些字段是为了实现与 XXtype 之间的相互转换),那么可以发现,iface实际上可以表示为如下的形式:
1 2 3 4 5
type iface struct { inter *interfacetype // 存储接口类型信息 _type *_type // 存储原始类的类型信息 data unsafe.Pointer // 存储原始类的其他信息 }
type structtype struct { // Type 信息 typ _type // Value 信息 pkgPath name // 4 字节 fields []structfield // 24 字节 }
以同一字段作为起始位置,这种做法在 C 中比较常见,其实就是通过统一字段加类型转换的方式实现了零成本的多态,例如 linux 链表,Lua LValue 的实现,都是使用了这种思想。go 中的指针虽然带有类型检查,不能强制转换,但是同样可以使用unsafe.Pointer来实现类似的“向上转换”。事实上,如果将structtype中 Value 信息部分视作一个unsafe.Pointer,那么就可以将其视作是一个eface类型。在 go 中,空接口就是使用这种方式来存储类型信息的,因为空接口没有任何方法,只需要进行类型转换和比较,因此只需要保留 Type 信息字段即可。另外注意到在 typ 字段后的字节(不同 struct 中字段名不同)都是一个指针类型,长度是四个字节,这个长度与iface中的 hash 字段是相互对应的。
在零成本抽样的 C++ 中以虚函数表的形式来实现了多态,然而这一功能并非 Zero Cost;同样地,在 go 中一个 struct 被赋值给一个它所实现的 interface,这个过程并不是零成本的。go 编译器隐藏了一些必要的工作:在编译时,编译器会增加一些代码来完成这些额外的工作。
在如下的代码片段中:
1 2 3 4 5 6 7 8 9 10 11
// B 是一个接口 type B interface {} // A 是一个结构体 type A struct {}
funcmain() { var b B a := A{} // 编译器会做许多额外工作 b = a }
当 struct A 被赋值给 interface B 时,经过 go 编译器编译后的代码,实际上会实现如下的逻辑:
若生成一个非空接口,将接口所需的interfacetype类型信息拷贝到栈上;
在符号表中寻找 A 类型及其实现的方法,以及 A 实例 data,将这些拷贝到栈上;
调用convT2E64(t *_type, elem unsafe.Pointer) (e eface)生成空接口,或调用convT2I(tab *itab, elem unsafe.Pointer) (i iface)生成非空接口。
这个过程实际上是在搜寻所需要的类型信息,并将类型信息与类型实例中各字段的值打包在一起,生成一个 XXtype 类型实例,最终使用“向上转换”生成接口实例。这个过程中发生了值的拷贝,因为利用unsafe.Pointer实现“向上转换”的前提是数据是连续的。无法确定 A 实例中值在内存中的地址前有足够的空间来分配生成接口所需的字段,因为需要将 A 实例的值拷贝到内存中的其他区域。可以看到,struct 到 interface 的转换其实是一个代价较大的操作。
funcValueOf(i any) Value { if i == nil { return Value{} } // 防止 GC,这里不需要关心 escapes(i) // 关键过程发生在这里 return unpackEface(i) }
funcunpackEface(i any) Value { // 取得空接口中的原始数据 e := (*emptyInterface)(unsafe.Pointer(&i)) // NOTE: don't read e.word until we know whether it is really a pointer or not. t := e.typ if t == nil { return Value{} } // 生成标志位 f := flag(t.Kind()) if ifaceIndir(t) { f |= flagIndir } // 将类型,数据,标志位进行拼接 return Value{t, e.word, f} }
这个过程中仍然是发生了两次拷贝,一次是 struct 传入 any 接口,一次是创建 Value 结构体。注意到,Value 这里使用的是复制后的数据,因此如果想使用反射来修改原数据,一定要传入指针。
取字段
反射中的取字段是将Value类型向下转换来实现的。在Value.ptr字段中存储了 XXtype 除类型头外的所有信息,在获取 Value 的基础上再使用“向下转换”可以获取类型具体,我们以获取 struct 中字段个数的方法为例:
1 2 3 4 5 6 7 8
func(v Value) NumField() int { // 通过 flag 字段检验类型 v.mustBe(Struct) // Value 向下转换,得到 structType tt := (*structType)(unsafe.Pointer(v.typ)) // 返回 structType 中的信息 returnlen(tt.fields) }