当程序需要读取标准输入时,用户输入的字符串会被显示在终端界面上,在按下回车键之后才能够被程序读取。但是在一些场景下,这种交互逻辑是不合适的,例如需要将用户输入的密码进行隐藏,或者是根据用户已有的输入进行自动补全。这些功能的实现并不依赖于传统的标准输入交互,而是需要定义一套自己的交互逻辑。本文将介绍这种功能背后所用到的一些知识。
IO 控制层
当我们在终端中输入字符串时,字符串明明是被输入到标准输入,那么为什么会显示在标准输出呢?以及为什么程序不能够实时地接收到用户的输入呢?这是其实是因为用户在键盘上的输入并不会被直接写入到程序的标准输入中去,而是需要先经过一个 IO 控制层。IO 控制层中有默认的交互逻辑用于缓存并处理用户的输入。
IO 控制层定义了一套默认的用户输入准则,能够大大减少交互程序的设计复杂度。在交互性程序中,用户的输入并不能够保证一定正确,因此 IO 控制层会先将键盘输入写入到自身的缓冲区,并且将这些字符写入到程序的标准输出上,等到用户按下回车才会将缓冲区中的输入发送给用户程序,这样程序就不需要关心删除用户错误输入的逻辑。当用户按下退格时,IO 控制层会删除掉缓冲区中的相关字符串,并且覆盖标准输出中的信息。在通常的终端中,已经输出的信息是不能够删除的,这其实也是 IO 控制层的默认规则——为了防止用户删除过多的相关消息。但事实上,在命令行终端上,所有的字符都是可以删除的,例如贪吃蛇游戏就是利用相关的功能来实现的。
在另一方面,IO 控制层还需要处理一些控制信号,例如键盘中的 Control-C、Control-Z 信号、方向键等。当 IO 控制层收到键盘上的这些指令时,会生成相应的 Signal 并使用 kill 命令发送给程序。
IO 控制层的相关功能存储在Termios结构体中,当用户不需要 IO 控制层中的某些功能时,可以使用系统调用ioctl()函数来对其进行更改。一些需要实时交互的程序中,例如游戏,可以通过设置Termios中的标准模式标识位来关闭按行缓冲的模式,实时接收用户的输入。在不需要进行输入回显的情景下,例如输入密码,可以设置Termios中的回显为关闭状态,防止输入被打印到标准输出上。
Shell 命令补全
Shell 的命令补全是依赖于 GNU Readline 的,可以将后者理解为 IO 控制层的个性化定制版本。它通过设置 IO 控制层的相关参数,关闭了默认功能,并且自行实现了输入的处理逻辑。在标准的 IO 控制模式中,用户按下 Tab 键意味着输入一个制表符,而在 Shell 语境下,当用户按下 Tab 键时,会根据当前的输入进行命令补全。仔细梳理一下命令补全所需的功能,可以概括为以下几点:实时获取用户输入、缓存用户输入、补全字典、字符串显示以及抹除的功能。前面几条比较容易接触到,自行维护一个输入缓冲区以及前缀树即可,而字符串的显示以及模式则需要用到与屏幕控制码相关的内容。
屏幕控制码是终端中用于控制输出显示的特殊字符串,它可以用于控制屏幕上的光标位置、颜色、显示内容等相关功能。例如将一个光标移动到终端的 y 行 x 列,就可以通过将字符串"\033[y;xH"写入标准输出来实现。Readline 中的补全功能其实是通过读取光标位置、移动光标、打印待补全字符串、恢复光标到最初位置,这一系列操作来完成的,这些操作都是通过屏幕控制码来完成的。
1 | void printStringToComplete() { |
以上的代码就可以实现在当前输入的下一行打印出一行字符串并且返回到原始的输入位置。由于这段代码的处理速度非常快,因此在用户眼中是一个整体的过程。除了 Shell 中的命令补全,vim 中的相关操作同样也是使用这种技术路线来实现的。
终端与 Shell
命令行终端与 Shell 是两个经常容易混淆的概念,但实际上两者的位置是不同的。Shell 的软件位置其实是位于命令行终端的上层,或者说后端。命令行终端的职责更加偏向于处理 IO 设备的各种输入,通过 IO 控制层(或 Shell 自定义的处理逻辑)将其转换为操作系统中的可读语言(各种命令符号),然后将处理后的信息输入到 Shell 程序的标准输入中。而 Shell 的职责则是读取经过处理的输入,按照既定的逻辑调用操作系统的各种接口,最终实现相关的功能。
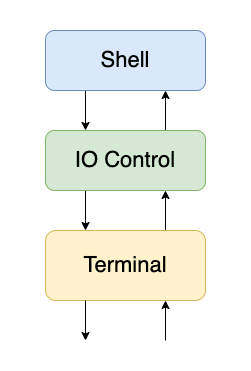
事实上,终端不止有命令行终端一种,物理终端同样也是终端的一种。在 IO 控制层中,有一些命令是用于调节输入的波特率等参数的,这些参数只适用于物理终端。终端的意义在于“输入的转换”,而在命令行终端中,这一职责其实被淡化了,因此也就容易与其他概念进行混淆。