有时候多个 SQL 语句的结构可能类似,只是某些过滤条件不同,例如SELECT col FROM table WHERE col > 1和SELECT col FROM table WHERE col > 2语句,此时可以先将 col_val 使用占位符 ? 替代传入数据库,得到语句SELECT col FROM table WHERE col > ?进行编译,然后再将 col_val 作为输入参数执行编译文件;这个过程叫做 SQL 的预编译。
sqlite3_exec() → A wrapper function that does sqlite3_prepare(), sqlite3_step(), sqlite3_column(), and sqlite3_finalize() for a string of one or more SQL statements.
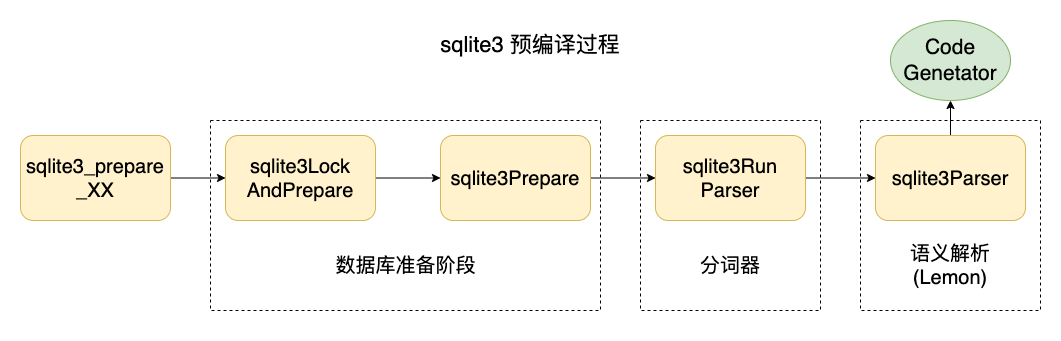
/* ** Run the parser on the given SQL string. */ intsqlite3RunParser(Parse *pParse, constchar *zSql){ int nErr = 0; /* Number of errors encountered */ void *pEngine; /* The LEMON-generated LALR(1) parser */ int n = 0; /* Length of the next token token */ int tokenType; /* type of the next token */ int lastTokenParsed = -1; /* type of the previous token */ sqlite3 *db = pParse->db; /* The database connection */ int mxSqlLen; /* Max length of an SQL string */ Parse *pParentParse = 0; /* Outer parse context, if any */ #ifdef sqlite3Parser_ENGINEALWAYSONSTACK yyParser sEngine; /* Space to hold the Lemon-generated Parser object */ #endif VVA_ONLY( u8 startedWithOom = db->mallocFailed );
if( pParse->pNewTable && !IN_SPECIAL_PARSE ){ /* If the pParse->declareVtab flag is set, do not delete any table ** structure built up in pParse->pNewTable. The calling code (see vtab.c) ** will take responsibility for freeing the Table structure. */ sqlite3DeleteTable(db, pParse->pNewTable); } if( pParse->pNewTrigger && !IN_RENAME_OBJECT ){ sqlite3DeleteTrigger(db, pParse->pNewTrigger); } if( pParse->pVList ) sqlite3DbNNFreeNN(db, pParse->pVList); db->pParse = pParentParse; assert( nErr==0 || pParse->rc!=SQLITE_OK ); return nErr; }
Assertion failed: (f == nullptr || dynamic_cast<To>(f) != nullptr), function down_cast, file casts.h, line 94.
// 对应 protobuf 代码段 template<typename To, typename From> // use like this: down_cast<T*>(foo); inline To down_cast(From* f){ // so we only accept pointers // Ensures that To is a sub-type of From *. This test is here only // for compile-time type checking, and has no overhead in an // optimized build at run-time, as it will be optimized away // completely. if (false) { implicit_cast<From*, To>(0); }