在 Redis 的设计中,用户可以使用 Lua 脚本来完成拓展功能,实现一些 RESP 协议中不提供的操作,这些复杂功能往往需要操作多个键值对,并且操作具有上下文关系,如限流算法、简单事务等。
在 Redis 官方手册中的介绍中,使用 Lua 脚本具有如下优点:
- 逻辑运行在服务端处而非客户端处,减少了 C/S 之间传输的网络延迟;
- Lua 脚本独占服务器运行权,能够保证脚本执行的原子性;
- 能够组合使用 Redis 支持的现有操作以完成更加复杂的逻辑。
在《Redis 设计与实现》一书中,作者详细地讲述了 Lua 脚本虚拟环境的搭建、Lua 脚本的运行流程;但是书中较少展示Redis 的源码,如果对 Lua 了解较少,可能会对该部分的具体实现过程较为困惑。本文将以 Redis 6.2.6 版本为例,介绍 Redis 中 Lua 脚本部分的实现。
Lua 脚本简介
Lua 是一种脚本语言,它使用标准 C 语言编写,具有很强的嵌入能力,能够作为“胶水语言”来为应用程序提高扩展性。除了 Redis 以外,Nginx 也同样适用了 Lua 来支持拓展功能。
Lua 语言的一个重要特性是它支持 C/Lua 函数之间的相互调用,这种相互调用是依赖于 Lua 虚拟机的栈特性实现的。下面以一个 demo 来简述 Lua 虚拟机中的栈特性。
1 | static int l_Replace(lua_State *L) { |
这段函数的输出结果为:
1 | Read From Lua: original |
当 Lua 中需要调用 C/C++ 函数时,需要使用 Lua 标准库中的lua_register函数将相应的函数注册到 Lua 虚拟机中。与传统的函数调用方式不同,Lua 中并不是依赖于 C/C++ 函数的返回值来进行值传递,而是在调用过程中创建一个栈,需要 C/C++ 函数将需要返回的值压入栈中,当该函数运行结束后,再将栈中的值作为函数的返回值;而 C/C++ 的返回值则用于表示是否执行成功,如果 return 0,则代表值 nil。
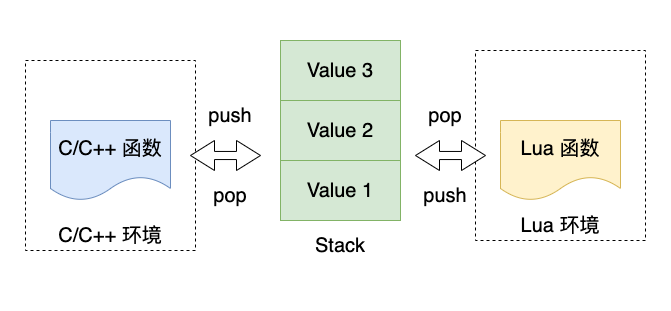
这种设计解决了 Lua 这种动态类型语言与 C/C++ 这种强类型语言之间值传递的问题,并且屏蔽了彼此之间的内存差异。但是这种方式使得 C/C++ 代码中需要嵌套大量操作 Lua 虚拟机的代码,具有一定的编程难度,比较好的一种做法是设置专门的模块作为中间层与 Lua 虚拟机进行交互,避免其他模块代码直接与 Lua 虚拟机进行耦合。这一思想在 Redis 源码中也有所体现。
Redis 中 Lua 虚拟环境的构建
虚拟环境的构建流程
Redis 中 Lua 虚拟机环境的创建是在scriptingInit函数中完成的,函数比较简单,将代码简化后,可以分为以下几个阶段:
1 | void scriptingInit(int setup) { |
初始化函数虽然较长,结构为线性结构,逻辑也比较简单,初始化函数中的几个阶段分别完成了如下工作:
- 使用 liblua 库函数创建 lua 虚拟机环境;
- 加载 Lua 基础函数库与表格库,并移除
loadfile和dofile函数,防止引发安全问题; - 创建一个 dict 用于保存 sha-script;
- 在 Lua 中创建 redis 表,并将 C 函数注册到该表格中,从而实现
redis.call接口; - 更替 random 函数库,保证随机函数在不同主机上生成相同的序列;
- 创建一个 fake 客户端,用于交互 redis 数据库;
- 设置全局保护,禁止设置全局变量;
- 将已经完成设置的 Lua 环境保存到 server 结构体中。
全局变量保护的实现
全局变量保护是许多 Lua 虚拟环境中都会完成的工作,利用的原理也大都相似——通过修改 _ENV 表中 _G 表中 metatable 来实现。metatable 是 Lua 表中的一个特殊表,它的每个字段中都存储了控制当前表一些行为的函数,如 __index字段 控制索引操作、__add字段控制表的相加操作。当需要对一个表进行操作时,LVM 将会查询该表的 metatable 是否有相关控制字段,若有该控制字段,会按照字段中存储的函数来执行操作。
基于元表的这一原理,通过修改 _G 表中 metatable 的 __newindex 和 ``__index`字段,就可以实现对插入和读取全局变量的保护。Redis 中实现该行为所使用的 Lua 脚本为:
1 | local dbg=debug |
由于 Redis 中所有的用户脚本都是被包裹在名为 f_sha 的函数中运行的,这里通过修改元表中的行为,不允许在非 main 以及非 C 条件下设置全局变量、访问不存在的全局变量;这样就实现了全局变量的保护。
redis.call 的实现
这里介绍一下redis.call()接口的实现。在 Lua 中,函数是一等公民,可以作为值被放入到哈希表中,然后从哈希表中取出并调用。redis.call()其实是一种 Lua 语法糖的写法,其原始的写法应该是redis['call'](),即从 redis 哈希表中取出键为 call 的函数值并调用。在环境初始化过程中,redis.call最终会绑定到luaRedisGenericCommmand函数上,该函数负责与 redis 数据库进行交互,Lua 环境下并不会直接与 C 环境下的 redis 数据库进行交互。
luaRedisGenericCommmand函数总长度约为 300 行,大部分逻辑为类型检查、异常处理等。剔除这些部分,仅仅保留主执行逻辑,我们可以把该函数分为以下几个阶段。函数中所有的参数检查都已经被删除。
1 | int luaRedisGenericCommand(lua_State *lua, int raise_error) { |
整体来说,该函数的逻辑也较为简单:从 Lua 栈中取出参数——调用 redis 命令表——将结果压入 Lua 栈中。函数中使用了一个 fake 客户端与数据库部分进行交互,因此luaRedisGenericCommand函数中必须要在 Lua 类型与 RESP 类型之间进行两次类型转换,但是这样的设计却有更多的优点:
- 避免重写数据库操作函数,降低了工程量;
- 共用操作函数,保障了 Lua 脚本与其他命令执行结果的一致性;
- 加入了中间层,降低了 Lua 环境与 C 环境的耦合度;
由于 Lua 语言本身是不含错误处理的,因此 Redis 额外设置了 pcall 用于包裹命令的执行,通过操作 Lua 栈的形式来进行错误的传递。当 Lua 脚本中使用redis.pcall时,luaRedisGenericCommand函数中的参数raise_error会被设置为 1,如果在命令执行过程中发生了错误,那么将会在最终的清理阶段通过luaRaiseError函数主动将错误信息压入到 Lua 栈中,以此来达到错误传递的目的。
eval 族函数的一些实现
Redis 中 eval 族命令最终都会调用evalGenericCommand,该函数的细节部分较多,这里将函数分为几个部分来讲述,以下代码片段在非标明前提下均来自于evalGenericCommand函数。
脚本的存储与编译
Redis 服务器提供了 Lua 脚本的复用功能,所有的脚本都会以 f_sha 的形式命名并存储在字典以及 Lua 环境中,其中 sha 是脚本经过 sha1hex 算法后计算得到的 40 位字符串。在调用脚本时,Redis 会直接尝试在 Lua 环境中使用 f_sha 来查找函数,若未找到,才会进行脚本的初始化。
1 | funcname[0] = 'f'; funcname[1] = '_'; |
在luaCreateFunction函数中,用户发送的脚本会被处理,并写入到 Lua 环境中的全局表中。假设用户所发送的 Lua 脚本内容为 function_body,那么最终将会被拼接为如下的形式:
1 | function f_<sha>() function_body |
如果对 Redis 手册较为熟悉,那么可以了解到所有的 Lua 脚本在服务器重启后都会失效,需要重新加载。这一特性从函数luaCreateFunction中可以了解到缘由。Lua 脚本在被创建时,会被注册到lua_scripts哈希表中,而这一哈希表对于 redis 来说是一个“二等公民”,它并不享有数据持久化的功能,在每一次重启时,redis 并不会自动导入之前已经载入的脚本。Lua 脚本相关的持久化功能只会被用于主从复制等场景。
脚本运行
Lua 脚本的运行在 C 代码中的体现比较少,在经过脚本的存储与编译后,只使用了如下代码来运行脚本:
1 | // 将 KEYS 和 ARGV 作为全局变量放入 Lua 环境 |
由于脚本内容和输入参数已经被送入到了 Lua 虚拟机的栈中,这里直接使用了lua_pcall执行脚本,运行中需要访问数据库的操作将会使用已经注册到 Lua 环境中的 redis 族函数。若脚本在运行中发生错误,那么 Lua 栈顶部将会存储错误信息,在清理阶段将会收集信息并返回客户端。
超时检测
Redis 中所有用户命令的执行都是单线程串行的,为了防止单个 Lua 脚本运行时间过长阻塞服务端,Lua 模块中提供了脚本运行超时功能,当脚本运行超时后,用户可以使用 script kill 命令来强行结束脚本。这一功能是通过 Lua hook 来实现的,在evalGenericCommand函数中使用lua_sethook(lua,luaMaskCountHook,LUA_MASKCOUNT,100000);代码将函数luaMaskCountHook作为 hook 注册到 Lua 环境中,每执行 100000 条语句,Lua 将强制执行一次该函数。
1 | void luaMaskCountHook(lua_State *lua, lua_Debug *ar) { |
脚本的运行时间是由该函数进行计算的,当脚本运行超时时函数将会输出一条日志,并且允许其他客户端强行中断脚本。中断一个正在运行的脚本是有条件的,必须确保当前执行的脚本没有进行过写操作,否则可能会严重影响数据库的安全性,甚至让数据库处于中间状态。Redis 中是通过记录脚本运行状态来判断脚本是否执行过写操作的,即标识位server.lua_write_dirty。在 Lua 脚本准备执行写操作时,会将该标识位置为 1,此时将不会允许脚本被中断。
Redis 同样会在该 hook 函数中来执行中断脚本的逻辑。当脚本发生超时后,每次执行 hook 函数,都会调用一次特殊的事件处理函数processEventsWhileBlocked:
Redis 的事务执行是单线程的,那么当 eventLoop 正在执行脚本时,为什么 Redis 还可以处理其余命令。Redis 并没有为 Lua 脚本单独开辟线程来运行,而是利用 Lua 环境中注册的 hook 函数来执行的。在 hook 函数中调用了processEventsWhileBlocked:
1 | void processEventsWhileBlocked(void) { |
processEventsWhileBlocked每一次被调用时都会最多处理四个已经解析完毕的客户端命令。在阻塞状态下,Redis 服务器将会只允许一部分命令执行,这些命令不影响数据库的状态或者用于关闭正在运行的脚本,其余命令将会被拒绝执行。允许被执行的命令如下:
1 | int processCommand(client *c) { |
在允许被执行的命令中,auth, hello, replconf, multi, discard, watch, unwatch, reset 都不会对数据库产生任何影响,其余的两个命令则是用于关闭脚本运行。
随机命令检测
Redis 对 Lua 脚本环境下的随机命令有所限制,根据官方手册:Redis 不允许在 Lua 脚本中随机命令发生在写命令前,单独的随机命令不受影响;这是为了防止同一份 Lua 脚本在不同实例中的执行结果不同。例如,一个脚本的执行逻辑是随机获取 100 个键,并将其中键值最小的 10 个键删除;由于每个实例中随机获取的键不同,最终可能会导致不同 Redis 实例的状态不同。但是先写入,后随机读取的情况则是允许的,例如先更新一个键,然后随机读取 10 个键;这不会造成 Redis 实例状态不同。
这一功能的实现原理同脚本中断,也是使用标识位来实现的。这一功能的实现位于luaRedisGenericCommmand函数中,处于获取命令后的检查阶段:
1 | int luaRedisGenericCommand(lua_State *lua, int raise_error) { |
可以看到这一段函数的逻辑是在写操作中检查if(server.lua_random_dirty == 1),因此先执行写操作,后执行随机操作是被允许的。但是,Redis 中实现的这一冲突检查并没有判断写操作是否是依赖于随机操作的,哪怕写操作与随机操作之间毫无关系,同样也会被报错;例如先随机读取 100 个键,然后删除掉特定的键,这样的逻辑是不被允许的。
另外,值得注意的是,这段逻辑中只检查了 Lua 脚本中的 redis 命令是否为随机命令,并不会检查 Lua 脚本中是否使用了随机函数。这是因为在 Lua 环境初始化阶段将math.rand函数已经被更替为 redis 的实现;redis 的随机函数实现中,只要保证使用相同的随机数种子,就能够在不同的主机环境下生成相同的随机数序。因此能够确保 Lua 脚本中的随机函数在不同主机下运行结果相同,不需要进行检测。
Redis 这里的实现是非常巧妙的,除了 Redis 选择的这种方法外,还有其他的方式可以完成随机函数的检测。其一是直接通过扫描脚本内容来实现随机函数的检测,这种方法能够在脚本运行前完成推断,但是需要依赖于语义分析,不仅实现困难,而且运行性能比较差。其二是通过覆盖 Lua 环境中的随机函数,在调用随机函数时更改server.lua_random_dirty标识位,这种方法的性能损耗比较小,但是也有一个比较隐秘的缺点——相比 Redis 实现,当用户只使用 Lua 随机函数时,需要中断脚本的运行。Redis 的实现方法基本上是无副作用的,并且 Lua 环境中并没有使用与数据库相同的随机种子,这也在一定程度上保护了数据库的安全性,防止通过脚本来推断出 Redis 数据库使用的随机种子。
多机环境下的 Lua 脚本
在单机环境下,Redis 对 Lua 模块的限制较小,但是在多机环境下,为了保障数据库的安全性,Redis 对 Lua 模块加入了一些限制条件。
Replica 环境下的限制条件
Replica 环境下的限制条件主要有以下几点:
- 随机命令与写命令的顺序问题:随机命令不能发生在写命令之前,即使写命令不依赖随机命令;
- 脚本的加载时机与 evalsha 命令的传播问题;
考虑这样一种情况:在构建复制集之前,Master 节点已经载入了一个 Lua 脚本。由于 Lua 脚本是一个“二等公民”,脚本本身并不会被 AOF/RDB 持久化记录;因此在构建出的复制集中,Slave 节点是不存在 Lua 脚本的源文件的。如果此时客户端直接使用 evalsha 命令来调用 Lua 脚本,Slave 节点中将无法执行该脚本,因为脚本并未在 Slave 节点中完成初始化。这有可能会导致主从节点的状态不一致。
为了解决这一冲突,在主从复制模式下,evalsha 会被转义为 eval 命令在主从节点之间传递,即传递全部 Lua 脚本。如果脚本过大,可能会影响网络带宽。
Cluster 环境下的限制条件
禁止访问不同分片
Cluster 环境下的限制更为苛刻:脚本只允许同时被访问当前实例所负责的分片。一方面是由于 Redis Cluster 设计,避免脚本重放,另一方面则是为了规避分布式事务的复杂性。
在 Redis Cluster 中允许一个分片中存在一主多从来实现故障恢复,保证高可用。考虑如下一种情况,分片 A 目前存活一主一从,而分片 B 目前存活一主;如果 Lua 脚本被允许访问不同分片上的数据,那么当分片 A 的主节点执行完毕后,分片 B 的从节点也需要执行一次脚本,这就需要付出一些额外的检查措施来保证分片 B 中的数据只会访问一次。这将会大大增加系统的复杂度,很难保证这一功能在加入之后会 0 bug。
另一方面,Lua 脚本中是允许使用 MULTI 事务的,如果支持访问多个分片的数据就必然会引入分布式事务的问题。Redis 本身定位是一个弱事务的内存数据库,必然不可能支持这一特性。
Redis 是在脚本运行中检查键是否存在于当前分片的,检查发生在luaRedisGenericCommand函数中:
1 | int luaRedisGenericCommand(lua_State *lua, int raise_error) { |
Redis 并不会在脚本运行前对所有需要访问的键进行检查,而是在运行中进行检查。因此,贸然访问不同分片上的值可能会让 Lua 脚本在运行中被中断,无法保证脚本逻辑的完整性。在分片模式下使用 Lua 脚本必须首先确保访问的所有键值对都处于同一分片,最好不要同时访问多个键。
在确定分片时,如果 key 值中存在{},那么会使用第一个{}中的值计算哈希槽;当集群模式下需要用 Lua 脚本来访问多个键时,可以将键值对以相同的开头命名,确保所有键值对都被分配到同一个哈希槽内。
禁止使用发布订阅
在 Lua 脚本中使用发布订阅同样也会因为脚本重放而引发一系列问题。由于 Cluster 模式中全局共享发布订阅频道,当脚本在主从节点之间传递时,会导致发布订阅命令被多次执行。
Redis Function
Redis Function 是 Redis 7.0 版本推出的全新功能,该功能是在原有 Lua 模块上的扩展与完善。Redis Function 将会被作为“一等公民”存储在数据库中,支持完整的持久化功能,这解决了 Lua 模块中的一些痛点。在使用 Redis 7.0 时,可以使用 Redis Function 来代替 Lua 模块。