kfifo 是 linux kernel 中一个简介优雅的无锁 ring_buffer 实现,能够保证在单线程写入和读线程读取场景下的线程安全。kfifo 的实现中使用了许多比较特殊的操作,值得进行学习。
kfifo 数据结构
kfifo 的数据结构非常简单,只有缓冲区指针及大小、读取写入偏移量,如下所示:
1 | struct kfifo { |
kfifo 实现巧妙之处主要有三点:
- 通过位运算判断 2 的幂以及向上取整为 2 的幂;
- 不进行模运算,而是利用溢出来实现读写偏移量计算;
- 使用内存屏障来保障单消费者、单生产者的无锁并发访问。
位运算部分
kfifo struct 中,要求缓冲区大小必须为 2 的幂,这是为了更加高效地判断计算出当前偏移量对应的内存位置。在 kfifo 初始化阶段,通过两个巧妙的位运算解决了判断 2 的幂以及向上取整为 2 的幂两个问题。
判断一个数是否为 2 的幂
在二进制存储中,如果一个数 n 是 2 的幂,那么这个数可以表示为 100···,除最高位外全部为 0。同样地,n-1 就可以表示为 0111…,除最高位外全部为 1。可以观察到 n 和 n-1 在二进制中,每一位都是相反的,因此 n & (n - 1) == 1。可以根据这种操作来利用位运算更快地判断一个数是否为 2 的幂。linux kernel 中的实现如下:
1 | static inline bool is_power_of_2(uint32_t n){ |
将一个数取整为 2 的幂
linux kernel 中的实现如下:
1 | // 求大于一个数的 2 的幂次数 |
这本质上是利用二分查找的原理,使用状态机的一种实现。主要的巧妙之处是利用了左移操作将每一次二分查找的分支进行了合并,使得代码变得更为简洁。
利用溢出实现读写偏移量计算
对一个数取模,从而使其保持在一定范围内,是常见的操作数组、缓冲区等长度固定数据结构的操作。但相对来说,取模的运算速度会相对较慢。kfifo 为了实现更快的偏移量计算,并没有使用取模操作,而是使用位运算使长度溢出来实现的。
以写入为例,该部分的核心代码可以简化为(将部分进行了聚合处理):
1 | unsigned int __kfifo_get(struct kfifo *fifo, |
先忽略内存屏障,这里用到了几个小技巧。由于写入和读取的偏移量 kfifo->in 和 kfifio->out 都是无符号整形,即使 kfifo->in因为过大而发生了溢出,也能够保持kfifo->in - kfifio->out <= kfifo->size。 因为 unsigned long类型的加减是回环的。
1 | // m 是 unsigned long 最大值 |
另外一个比较巧妙的地方是,没有使用取模来计算偏移量,而是修改为了位运算的方式,这依赖于 kfifo 的缓冲区大小限定为 2 的幂。
1 | // 传统取模方式 |
在二进制中,kfifo->size 可以表示为 1000···,那么 kfifo->size - 1 就可以表示为 0111···;同样地,kfifo->in 也可以分解为 offset + n2,其中 n2 是 kfifo->size的倍数,offset 是 kfifo->in % kfifo->size。由于 n2 是 kfifo->size 倍数,所以其数据只分布在大于 kfifo->size 位数的部分,因此只需要截取 kfifo->in 小于 kfifo->size 位数的部分,就可以得到 offset。观察到,kfifo->size - 1在每一个小于 kfifo->size 的位上的值均为 1,那么只要进行运算 kfifo->in % kfifo->size ,超出 kfifo->size 位数的部分会被截去,而小于 kfifo->size 位数的部分会被保留,即得到 offset。
还有一个比较巧妙的点是没有使用 if 进行判断,直接使用了两个memcpy。这里是直接利用 memcpy 的第三个参数进行了控制,当第一次 memcpy 完全拷贝时,第二次 memcpy 将不进行任何操作。
内存屏障
在计算机操作系统中,一个读线程和一个写线程同时操作一个变量时不需要进行加锁的。在 kfifo 中,读操作与写操作分别只会更新 kfifo->out 和 kfifo->in,因此不会出现并发问题。
但是,参考《C++并发编程实践》第 123 页:“无论对象是怎么样的类型,对象都会存储在一个或多个内存位置上。每个内存位置不是标量类型的对象,就是标量类 型的子对象,比如,unsigned short、my_class*或序列中的相邻位域。当使用位域时就需要注意:虽然相邻位域 中是不同的对象,但仍视其为相同的内存位置。如图5.1所示,将一个struct分解为多个对象,并且展示了每个对象 的内存位置。”如下图,bf1 和 bf2 被保存在相同的位置。
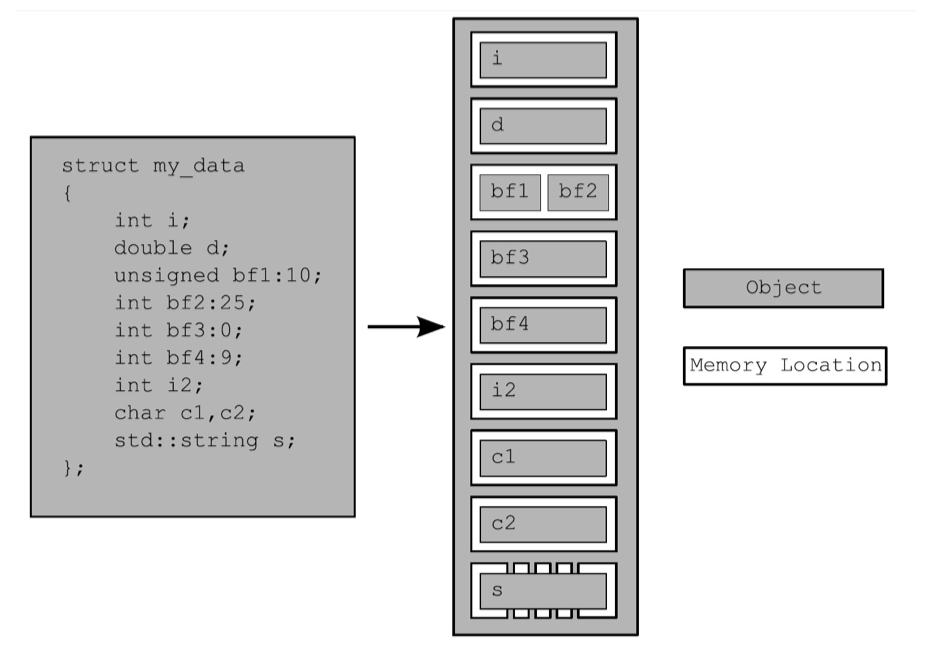
这种情况下,bf1 和 bf2 可能会有多个副本分别存储在不同 CPU 的 Cache 中,如果线程 th1 写入 bf1 的同时线程 th2 读取bf2,那么 th2 可能会读取到在 CPU Cache 中的过期数据。由于 kfifo 中的成员都是基本类型,它们很有可能会被存储在相同的内存位置,因此需要引入内存屏障来保证以下写入顺序:
- kfifo->data 写入数据;
- 更新 kfifo->in 值。
这也就是读取和写入操作中 smp_mb()的作用,用于强制保证内存的更新是全局的。