MongoDB 复制集同步过程
MongoDB Replica Set 是一种基于分布式选举和复制状态机的高可用架构,这一套模式虽然与 paxos、raft 协议非常相似,但实质上差异却非常大。raft 协议中,所有事务的提交都是线性的,所有节点会进行同步提交,因此可以保持很高的数据一致性,但是写性能会比较差;而 MongoDB 的复制集则是一种异步复制+选举算法的结合,通过调节事务的提交时间来完成数据一致性的保证。
基于 Oplog 的数据同步机制
与 raft 协议类似,MongoDB 中也是采用复制状态机的模式来进行数据复制,在 MongoDB 中用于节点同步的日志类型称为 Oplog。Oplog 其实并不是一种日志文件,而是 WiredTiger 中一个特殊的 Collection,这种特殊的模式使得 MongoDB 中应用层日志、数据、索引实际上是作为一个事务整体写入的。这种设计能够有效地规避应用层日志与数据库日志不相同的问题,这个问题在 MySQL 中有所体现,并且困惑了开发者相当长一段时间。对比 etcd 的实现,可以认为 etcd 是按照 raft 状态机的模式,在 raft 节点之上构建一个数据库;而 MongoDB 其实仍然是一个传统的数据库同步模式,是一个基于数据库引擎的复制模式,这是两者之间的核心差异。
Oplog 的异步复制
经过上一小节的讨论,MongoDB 的复制机制并不是 etcd 的模式,而是类似 MySQL 主从复制的模式。这样就能够更加轻松地理解为什么 Oplog 采取的一种异步复制的模式。
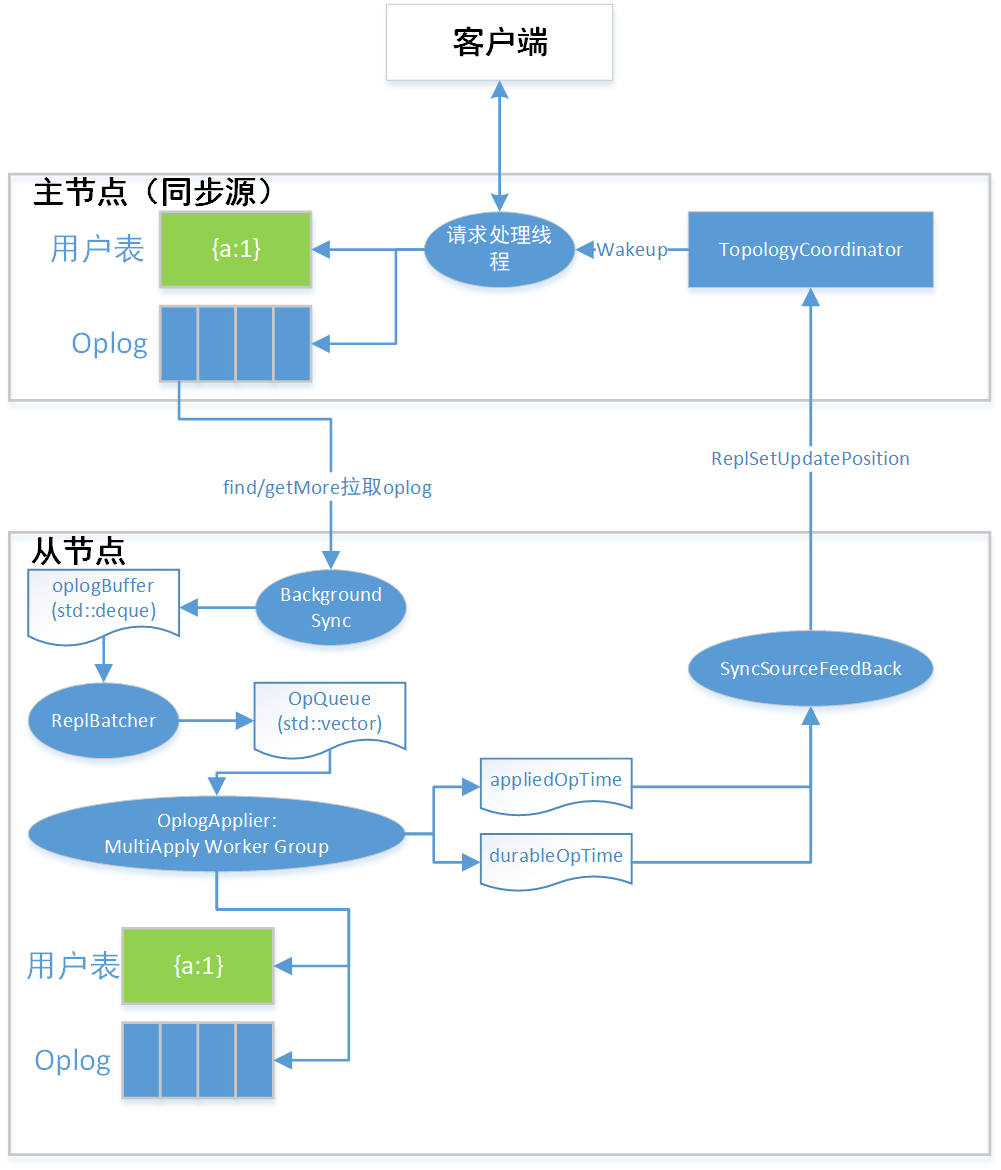
Oplog 的异步复制是由从节点发起的,每一个从节点都会有一个特殊的线程用于从主节点拉取 Oplog,我们这里称之为拉取线程。当拉取线程只负责完成 Oplog 的复制,并写入到本地的 Collection 中,当写入完成后拉取线程就会继续向主节点请求下一批 Oplog。拉取线程在拉取 Oplog 过程中不会发生任何的阻塞。
Oplog 的重放是由重放线程来完成的,根据设置 MongoDB 中可以存在多个重放线程来加快复制速度,默认的重放线程为 16 个。重放线程实际上是在模拟客户端的请求向数据库发送命令完成数据的复制。回放线程尽量累积大量数据才回放(批量并发执行效率高)。但是如果oplog比较少,会提前返回。但是极端情况下,可能会有最多阻塞1秒的情况。
当重放线程完成重放后,会直接通知主节点自身的当前版本。心跳与版本上报是两个不同的过程,因为心跳周期两秒的间隔时间过长,如果使用心跳上报会导致客户端请求长时间被阻塞。心跳只用于无请求时的保活操作。
选举机制
MongoDB 中的选举与 raft 算法也有着一定的区别。raft 算法中由于客户端请求必须到达多数节点才能够提交,因此在选举过程中需要考虑数据一致性的问题,防止数据回滚。而 MongoDB 中,客户端操作并不会因为未到达多数节点而提交失败,只会发生超时错误(超时错误不会导致回滚),因此 MongoDB 中的选举算法主要考虑如何更快地选择数据更多更新的节点,并且尽量保证不丢失数据。
MongoDB 选举机制中比较特殊的地方在于:当选举完成后,新选举的主节点会要求所有的从节点发送自身的最近数据,并且取这些数据的并集作为集群视图,raft 协议中则是直接按照主节点的状态机作为新视图。这点不同主要是考虑到每个从节点进行 Oplog 重放的顺序可能不同,虽然 Oplog 的拉取是严格按照次数的,但是在重放过程中由于使用了多线程重放,可能会有一部分线程阻塞,发生事务提交的重排。
网络分区的风险
当 MongoDB 复制集集群中发生主节点网络分区时,虽然集群中已经完成了选举,但主节点在当前的心跳周期仍然可以处理客户端的请求。
如果客户端的写入请求为 w:1,那么在这种情况下仍然是可以成功写入的,并且客户端并不会得到写入超时的通知,即客户端视角下无法得知异常发生,无法采取相关的异常处理操作。当主节点网络恢复后,这部分时间内发生的写请求会发生回滚,回滚的数据会被写入到回滚文件中,必须要人工进行数据维护。如果不使用高于 w:majority 的写入等级,就需要承受数据发生回滚的风险。
发生网络分区时,客户端的读请求会因为不同的 Read Peference 而发生不同的处理。在约一个心跳周期的时间范围内,MongoDB 只能够保证采取相同Read Concern 和 Read Peference 的读请求保持正确的读顺序。当Read Concern 和 Read Peference 不同时,可能会出现读请求R1读到主节点的过期数据,读请求R2 读到其他节点的正常数据,当 R2 时间早于 R1 时就会出现读操作的不安全性。 最好对相同的 Collection 采取相同的读设置来获取更一致的视图。